
Obvyr is a test execution tracking platform. It captures data from every automated test run and turns it into insight about test reliability over time: flaky tests, environment drift, and test suite health. If you’re not familiar with it, the features page and the problems it solves are good starting points, or there’s more background in the introductory post.
Today we’re opening registration to everyone. No waitlist, no approval process. But before I share the link, I want to share something I didn’t expect to learn while building it.
What the data reveals
When teams start seeing their test execution data for the first time, the most common reaction isn’t surprise. It’s recognition.
They already knew which tests they didn’t trust. They’d been quietly re-running them for months, building informal workarounds: the retry flag in the CI config, the test everyone knows to ignore when it fails on a Friday, the suite that gets skipped in the pre-release pipeline “just this once” that has been skipped seventeen times. That knowledge lived in Slack messages and team folklore, never written down because there was nowhere to write it.
What Obvyr does is give that knowledge a form. A failure rate. A pattern visible across the whole team.
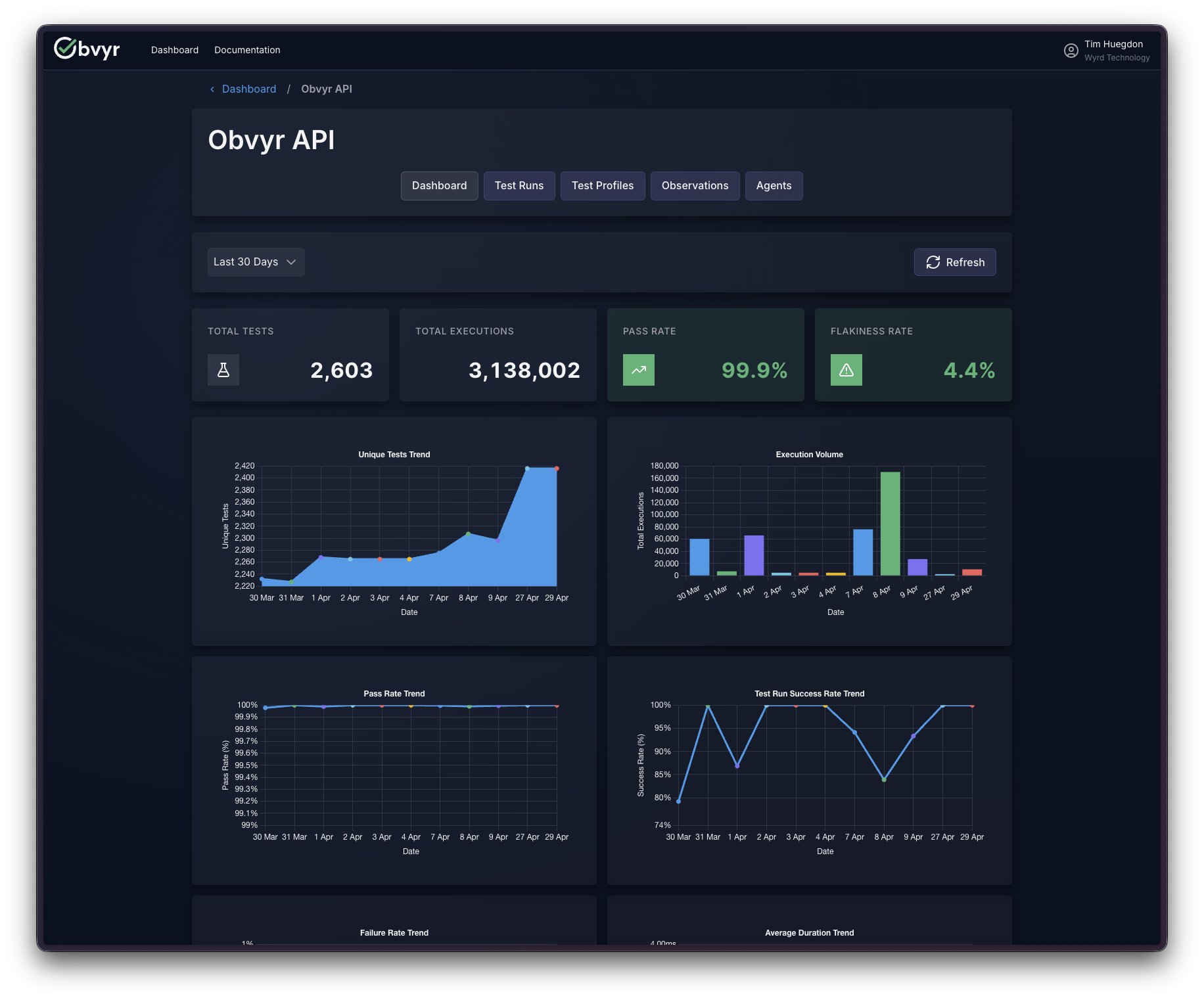
The data was never missing. Every CI pipeline generates a detailed record of what passed, what failed, and how long it took. It was just being thrown away the moment each pipeline finished, buried in logs that nobody was reading.
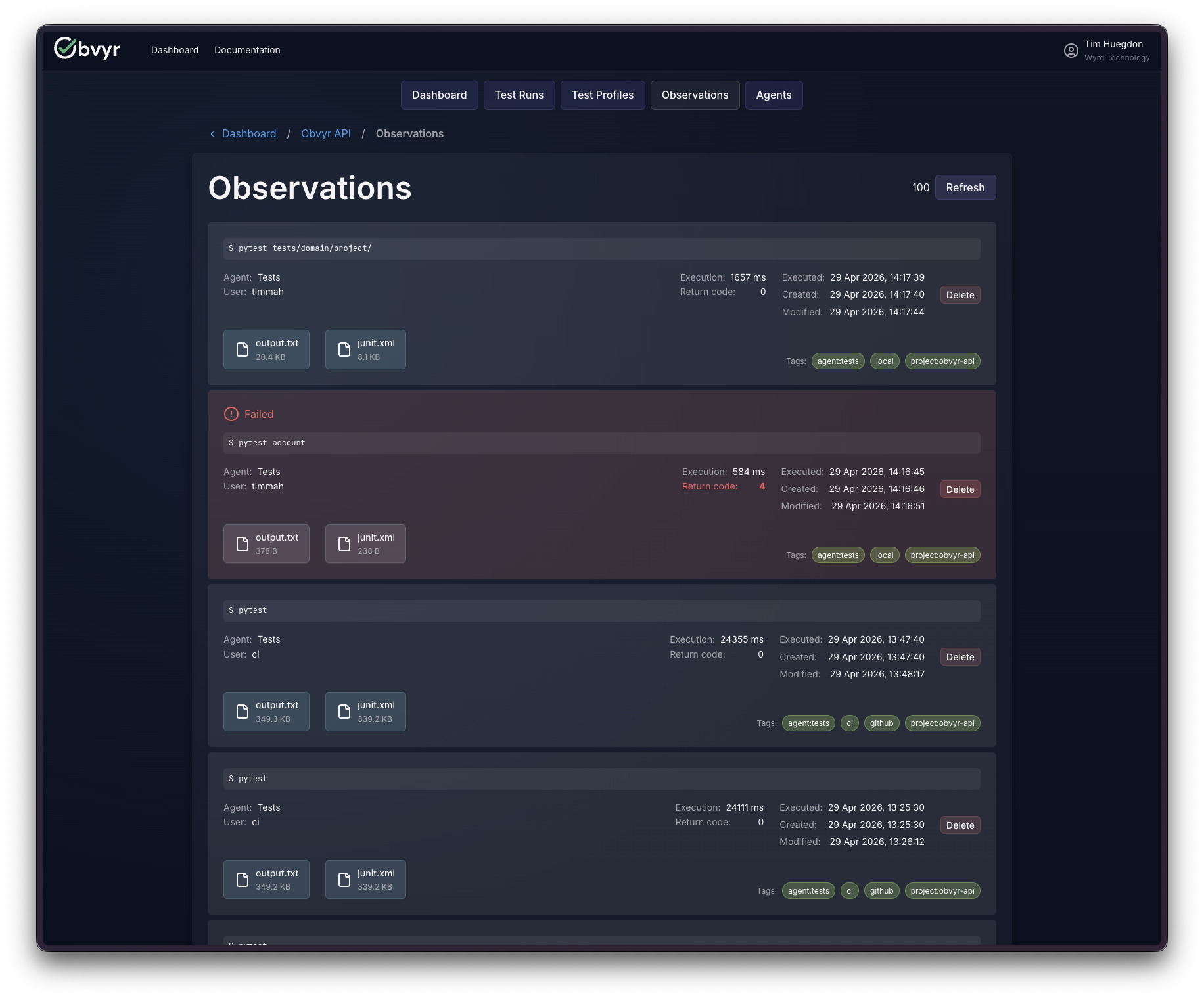
When you can see it accumulate, the question shifts from did the tests pass? to which tests do we trust, and is that improving? That second question requires history. Obvyr keeps the history.
We use it ourselves
The most useful thing I can tell you about Obvyr is that Obvyr is built with Obvyr.
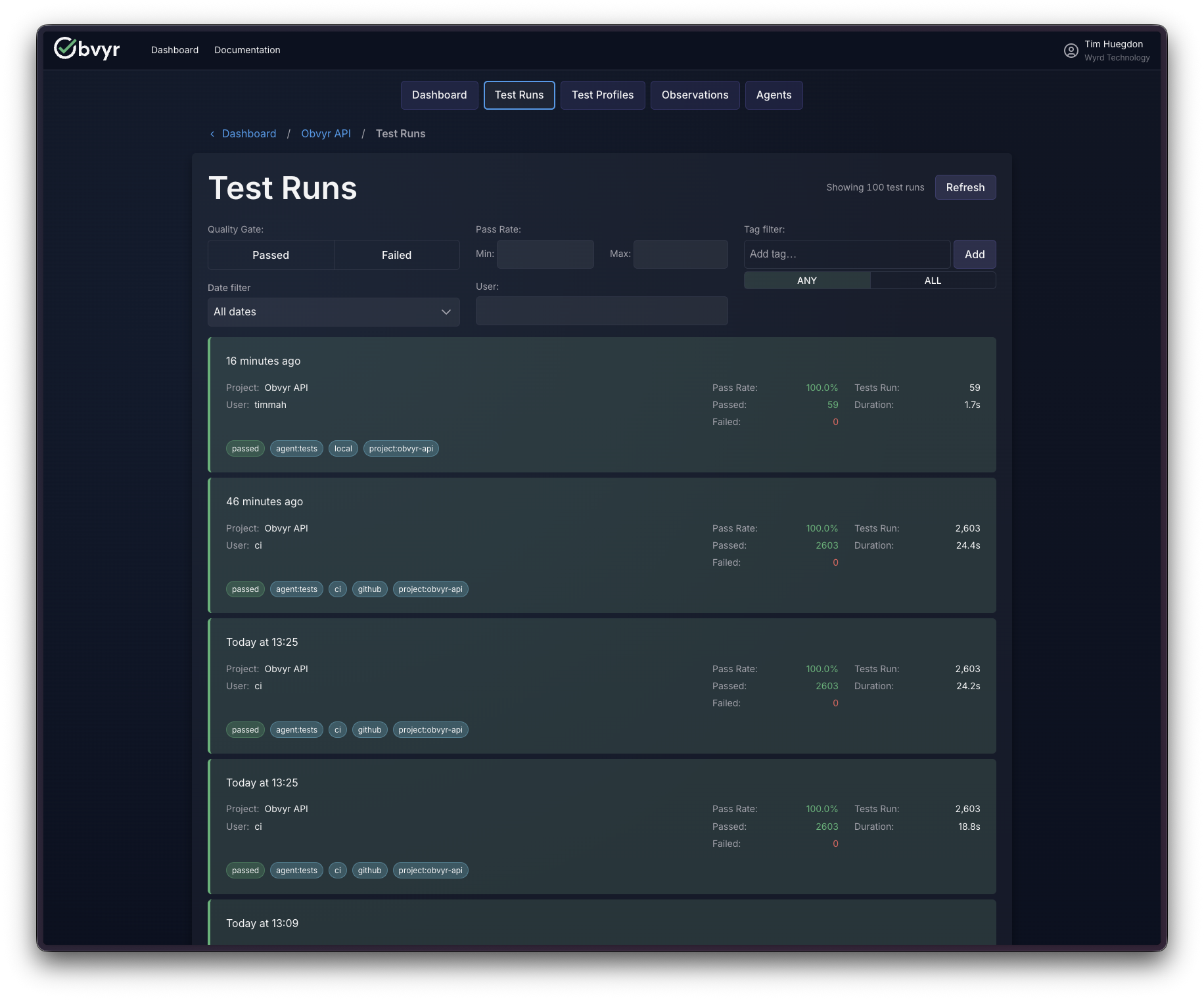
Every test run across our projects (the API, the CLI, the UI, the Gradle plugin) feeds into our own account. When a build fails in CI, the first place I look isn’t the pipeline logs. It’s our dashboard. Finding the specific test failure, with its full output and stack trace, takes seconds in the app; the same search through CI output, which is designed for machines to read rather than people, takes considerably longer. That alone has been worth it.
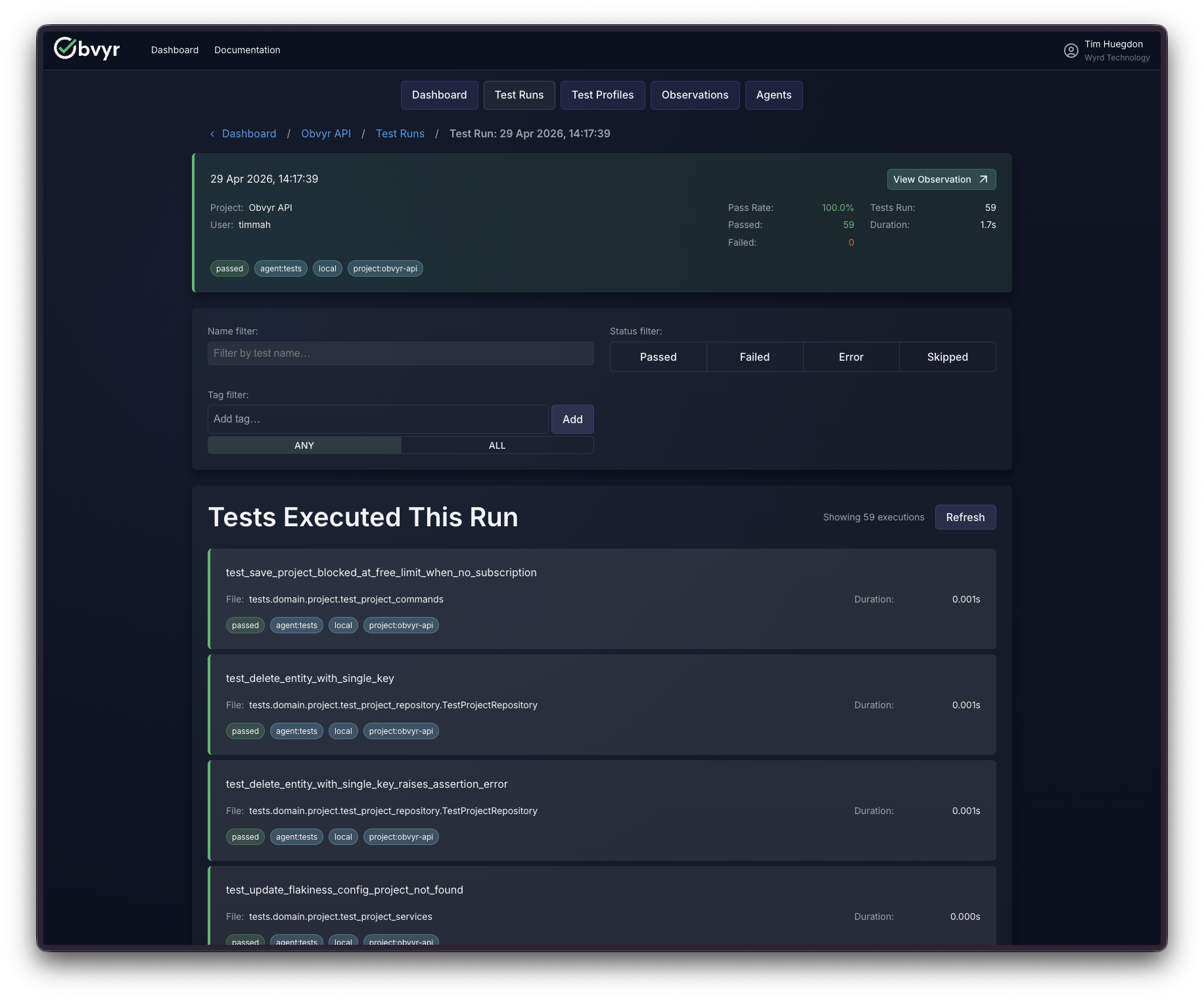
What I hadn’t anticipated was how useful the cross-project view would become. We have half a dozen active repositories. Being able to see test health across all of them in one place, and notice when a pattern in one project is showing up in another, is something I had underestimated. We built that feature because we thought teams would need it. It turned out we needed it too.
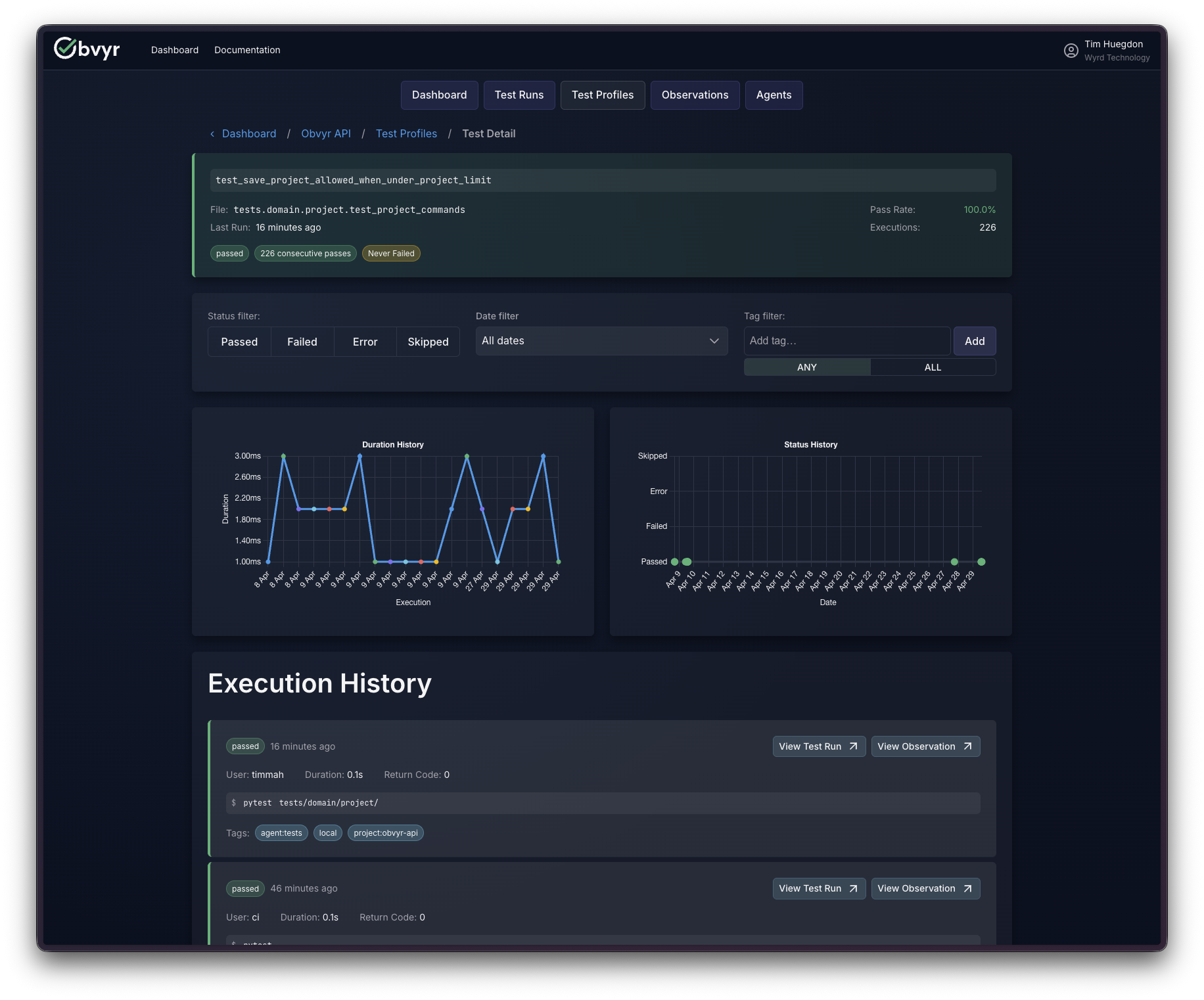
Using it ourselves also makes the gaps more concrete. We don’t have coverage data yet, and we feel that absence in our own workflow. It’s the next significant thing we’re building, and the fact that we want it ourselves is a reasonable sign we’re prioritising the right things.
Try it
Obvyr is now open to everyone, with a 14-day free trial.
If your team runs automated tests and you want to understand what that investment is actually worth, sign up and give it a try.
And if you try it and have thoughts about what’s working, what’s confusing, or what you wish it did, I’d genuinely love to hear from you. You can reach me at hello@obvyr.com.